
|
Библиотека дополнительных функций |
В этом разделе описываются функции, приведенные в книге Лаврова и Силагадзе и написанные на Лиспе. Эти функции входят в "джентльменский набор" функций, которые должны быть реализованы в любой версии Лиспа. Исключение составляет только макро FOR, который реализовал автор.
| Имя функции | Тип функции | К-во аргумен- тов | Тип аргумен- тов | Выполняемое действие |
| ADDIFNONE | EXPR | 2 | ANY | Проверяет, входит ли значение первого аргумента в список, заданный вторым аргументом. Если не входит, то возвращается список, заданный вторым аргументом, с добавлением в начало значения первого аргумента. В противном случае возвращается значение второго аргумента. |
| APPEND | EXPR | 2 |
1-LIST; 2-ANY |
Создает новый список, путем присоединения первого аргумента ко второму |
| ASSOC | EXPR | 2 |
1-ANY; 2-LIST |
Выбирает из ассоциативного списка, заданного вторым аргументом, первую пару, в которой первый элемент совпадает со значением первого аргумента. |
| ATOMLIST | EXPR | 1 | ANY | Возвращает Т, если значение аргумента есть список, составленный из атомов |
| ATTACH | EXPR | 2 | ANY | Функция выполняет те же действия, что и CONS, но значение функции закрепляется за ее вторым аргументом. У функции имеется побочный эффект. |
| CART | EXPR | 2 | LIST | Строит декартово произведение множеств , заданных первым и вторым аргументами. |
| COLLECT | EXPR | 1 | ANY | Перегруппировывает элементы списка-аргумента таким образом, чтобы одинаковые элементы стояли подряд. |
| COPY | EXPR | 1 | ANY | Создает копию своего аргумента |
| CYCLEP | EXPR | 1 | ANY | Проверяет, является ли значение аргумента функции циклической структурой. |
| DEFINE | FEXPR | 1 | LIST | Одновременное определение нескольких функций типа EXPR |
| DEFLIST | FEXPR | 2 |
1-LIST; 2-ATOM |
Одновременное задание нескольким атомам значений свойств с заданным индикатором. |
| DIFLIST | EXPR | 2 | LIST | Вычисляет разность множеств, заданных списками, соответствующими первому и второму аргументу. |
| DPAIR | EXPR | 2 | LIST | Функция работает аналогично PAIR, но значение первого аргумента заменяется значением функции (т.е. построенным ассоциативным списком) |
| DREMOVE | EXPR | 2 | ANY | Второй аргумент этой функции должен быть списком. Выполняется исключение из этого списка всех элементов, совпадающих с первым аргументом. |
| DREVERSE | EXPR | 1 | ANY | Функция выполняет те же действия, что и REVERSE, но разрушает свой аргумент. |
| EFFACE | EXPR | 2 | ANY | Второй аргумент этой функции должен быть списком. Выполняется исключение из этого списка первого элемента, совпадающего с первым аргументом. |
| EQUAL | EXPR | 2 | ANY | Проверяет совпадение значений своих аргументов. В отличие от встроенной функции EQ, применима не только к атомам, но и к произвольным списочным структурам. При совпадении значений возвращает T, в противном случае - Nil |
| EQUALSET | EXPR | 2 | LIST | Проверяет, равны ли множества, заданные списками, соответствующими первому и второму аргументам. |
| FIRST | EXPR | 2 | LIST | Среди элементов списка, заданого первым аргументом, выбирается тот, который раньше встречается в списке, заданным вторым аргументом. |
| FLAG | EXPR | 2 |
1-LIST; 2-АТОМ |
Заносит флаг, заданный значением второго аргумента, в список свойств каждого из атомов, входящих в список, заданный первым аргументом. |
| FLAGP | EXPR | 2 | АТОМ | Проверяет наличие в списке свойств атома, заданного первым аргументом, флага, заданного значением второго аргумента. |
| FLATTEN | EXPR | 1 | ANY | Устраняет скобочную структуру и точки, превращая S-выражение в одноуровневый список атомов |
| FOR | MACRO | 4 |
1-АТОМ; 2,3-FIXED; 4-LIST |
Простой оператор цикла. Параметр цикла задается первым параметром; начало цикла - вторым, конец - третьим. Шаг цикла всегда равен 1. Четвертый параметр задает список операторов, составляющих тело цикла. |
| FORALL | EXPR | 2 |
1-LIST; 2-F/LBD |
Фунция, заданная вторым (функциональным) аргументом, применяется ко всем элементам списка, заданного первым аргументом. Результат равен Т, если результат применения функционального аргумента к каждому элементу первого аргумента равен Т. |
| FORODD | EXPR | 2 |
1-LIST; 2-F/LBD |
Фунция, заданная вторым (функциональным) аргументом, применяется ко всем элементам списка, заданного первым аргументом. Результат равен Т, если результат применения функционального аргумента равен Т для нечетного количества элементов списка. |
| FORSOME | EXPR | 2 |
1-LIST; 2-F/LBD |
Фунция, заданная вторым (функциональным) аргументом, применяется ко всем элементам списка, заданного первым аргументом. Результат равен Т, если результат применения функционального аргумента хотя бы к одному элементу первого аргумента равен Т. |
| GETPROP | EXPR | 2 | АТОМ | Функция проверяет, есть ли у атома, заданного первым аргументом, свойство заданное значением второго аргумента. Если свойство есть - функция вернет в качестве значения это свойство. В противном случае функция вернет Nil. |
| INTERSECTION | EXPR | 2 | LIST | Строит пересечение множеств элементов списков, заданных первым и вторым аргументами. |
| LAST | EXPR | 1 | LIST | Выделяет последний элемент списка |
| LCYCLEP | EXPR | 1 | ANY | Проверяет значение своего аргумента на наличие цепочек по d-указателю. При наличии цепочки возвращает T, в противном случае - Nil. |
| LENGTH | EXPR | 1 | ANY | Возвращает длину списка (на верхнем уровне) |
| LEXORDER | EXPR | 3 | LIST | Сравнивает элементы списков, заданных первым и вторым аргументом, с использованием ORDER1. Если элементы списков, стоящих в одинаковых позициях первого и второго аргументов, различаются, то они сравниваются посредством ORDER1. |
| LEXORDER1 | EXPR | 3 | LIST | Функция работает аналогично LEXORDER, но третьим аргументом задается список списков, очередной элемент которого используется при необходимости сравнения элементов. |
| LISTP | EXPR | 1 | ANY | Если значение аргумента есть S-выражение, которое можно изобразить без употребления точек, функция возвращает T. В противном случае, функция возвращает Nil. |
| LUNION | EXPR | 1 | LIST | Строит объединение множества элементов из элементов списка, заданного аргументом. |
| MAKESET | EXPR | 1 | LIST | Строит список из неповторяющихся значений элементов списка, заданного аргументом. (то же, что и SETOF) |
| MAP | EXPR | 2 |
1-LIST; 2-F/LBD |
Аналогично MAPLIST, но всегда возвращается Nil. Имеет смысл в том случае, когда функция, заданная вторым аргументом имеет побочный эффект (например, печатает что-либо). |
| MAPCAR | EXPR | 2 |
1-LIST; 2-F/LBD |
Аналогично MAPLIST, но функция применяется не к хвостам списков, а к первым элементам. |
| MAPLIST | EXPR | 2 |
1-LIST; 2-F/LBD |
Функция, заданная вторым аргументом, последовательно применяется к значению первого аргумента, и ко всем спискам, полученным из значения первого аргумента путем отбрасывания первого элемента. Результатом функции является список полученных вызовов. |
| MEMB | EXPR | 2 |
1-ATOM; 2-ANY |
Проверяет, является ли атом, заданный первым аргументом, элементом списка, заданного вторым аргументом. Если является, функция возвращает T, иначе - Nil |
| MEMBER | EXPR | 2 | ANY | Проверяет, является ли первый аргумент элементом списка, заданного вторым аргументом. Если является, функция возвращает T, иначе - Nil |
| NCONC | EXPR | 2 | ANY | Функция выполняет те же действия, что и APPEND, но одновременно присваивает свой результат первому аргументу. |
| ORDER | EXPR | 3 |
1,2-АТОМ; 3-LIST |
Проверяет, встречаются ли атомы, заданные первым и вторым аргументами, в списке, заданном третьим аргументом в заданном порядке (в этом случае результат будет T, в противном случае - Nil) |
| ORDER1 | EXPR | 3 |
1,2-АТОМ; 3-LIST |
Работает аналогично ORDER, но при нарушении порядка возвращается атом ORDERUNDEF. |
| PAIR | EXPR | 2 | LIST | Строит ассоциативный список (список точечных пар) из элементов списков, заданных аргументами. |
| PAIRLIS | EXPR | 3 | LIST | Строит ассоциативный список из элементов списков, заданных первым и вторым аргументами и добавляет его к ассоциативному списку, заданному третьим аргументом. |
| POP | FEXPR | 1 | АТОМ | Результат вычисления функции полностью эквивалентен вычислению (SETQ A (CDR A)), где А - аргумент. |
| POPUP | FEXPR | 2 | АТОМ | Результат вычисления функции эквивалентен последовательному вычислению двух выражений: (SETQ A1 (CAR A2)) и (SETQ A2 (CDR A2)). В качестве результата функция возвращает Nil. |
| POSSESSING | EXPR | 2 |
1-F/LBD; 2-LIST |
Строит список тех элементов списка, заданного вторым аргументом, для которых истино значение, заданное первым аргументом. |
| PROP | EXPR | 3 |
1,2-ATOM; 3-F/LBD |
Если у атома, заданного первым аргументом, есть свойство, заданное значением второго аргумента, то функция вернет хвост списка свойств, следующий за найденным индикатором. Если свойства нет - будет произведен вызов функции, заданной третьим аргументом. Эта функция не должна принимать параметров. |
| PUSH | FEXPR | 2 |
1-ANY; 2-ATOM |
Результат вычисления функции полностью эквивалентен вычислению (SETQ A2 (CONS A1 A2)), где А1 - первый аргумент, А2 - второй. |
| PUTFLAG | EXPR | 2 | АТОМ | Помещает в список свойств атома, заданого первым аргументом, флаг, заданный значением второго аргумента. |
| PUTPROP | EXPR | 3 |
1-АТОМ; 2-АТОМ; 3-ANY |
Функция добавляет в список свойств атома, заданного первым аргументом, индикатор, заданный вторым аргументом и свойство, заданное третьим аргументом. |
| RANK | EXPR | 2 | LIST | Упорядочивает список, заданный первым аргументом в порядке, заданном вторым аргументом |
| REMFLAG | EXPR | 2 |
1-LIST; 2-АТОМ |
Удаляет флаг, заданный значением второго аргумента, из списка свойств каждого из атомов, входящих в список, заданный первым аргументом. |
| REMOVE | EXPR | 2 | ANY | Удаление ВСЕХ вхождений значения первого аргумента из списка, заданного значением второго. |
| REMOVEF | EXPR | 2 | ANY | Удаление ПЕРВОГО вхождения значения первого аргумента из списка, заданного значением второго. |
| REMPROP | EXPR | 2 | АТОМ | Удаляет из списка свойств атома, заданного первым аргументом, свойство, заданное вторым аргументом. Если такого свойства нет, список свойств атома не меняется. Функция возвращает значение первого аргумента. |
| REVERSE | EXPR | 1 | ANY | Переставляет элементы списка в обратном порядке (на верхнем уровне). |
| SASSOC | EXPR | 3 |
1-ANY; 2-LIST; 3-F/LBD |
Аналогично ASSOC, но в случае отсутствия ассоциации, выдается результат вызова функции, заданной третьим аргументом. Эта функция не должна принимать параметры. |
| SELECT | EXPR | 3 |
1-ANY; 2-LIST; 3-ANY |
Функция ищет значение первого аргумента в списке, заданным вторым аргументом на нечетных местах. Если значение найдено, то функция возвращает элемент списка, следующий за найденным. В противном случае возвращается значение третьего аргумента. |
| SETOF | EXPR | 1 | LIST | Строит список из неповторяющихся значений элементов списка, заданного аргументом. |
| SUBLIS | EXPR | 2 |
1-LIST; 2-ANY |
В выражении, заданном значением второго аргумента, заменяет все атомы на ассоциации из ассоциативного списка, заданного первым аргументом. |
| SUBSET | EXPR | 2 | LIST | Если каждый элемент списка, заданного первым аргументом, входит в список, заданный вторым аргументом, то функция возвращает T. В противном случае возвращается Nil. |
| SUBST | EXPR | 3 | LIST | Выполняет замену в выражении, заданном третьим аргументом все вхождения значения первого аргумента (на всех уровнях) на значение второго аргумента. |
| SUCHTHAT | EXPR | 2 |
1-F/LBD; 2-LIST |
Выбирает из списка, заданного вторым аргументом, первый элемент, для которого истино выражение, заданное первым аргументом. |
| SUCHTHAT1 | EXPR | 4 |
1-F/LBD; 2-LIST; 3,4-ANY |
Проверяет, содержится ли в списке, заданном вторым аргументом хотя бы один элемент, для которого истино выражение, заданное первым аргументом. Если такой элемент найден, то результатом будет значение четвертого аргумента. Если же такой элемент не найден, то возвращается значение третьего аргумента. |
| SUCHTHAT2 | EXPR | 3 |
1-F/LBD; 2-LIST; 3-F/LBD |
Проверяет содержится ли в списке, заданным вторым аргументом, элемент, для которого истино выражение, заданное первым аргументом. Если такой элемент найден, то к хвосту списка, начиная с найденного элемента применяется функция, заданная третьим аргументом. Если элемент не найден, возвращается Nil. |
| TCONC | EXPR | 2 | ANY | Функция помещает значение своего первого аргумента в конец очереди, заданной вторым аргументом |
| UNION | EXPR | 2 | LIST | Функция вычисляет объединение множеств, заданных списками-аргументами. |

|
ADDIFNONE |
Функция ADDIFNONE проверяет, входит ли значение первого аргумента в список,
заданный вторым аргументом. Если не входит, то возвращается список, заданный вторым аргументом,
с добавлением в начало значения первого аргумента. В противном случае возвращается значение второго аргумента.
Вот примеры работы с функцией ADDIFNONE :
(addifnone 'a '(a b c)) ==> (a b c) (addifnone 's '(a b c)) ==> (s a b c) (addifnone 'a nil) ==> (a) |
В последнем случае происходит присоединение атома a в начало пустого списка.
|
|
APPEND |
Функция APPEND принимает два арумента. Первый из них должен быть списоком. Второй может
быть любым S-выражением. Функция возвращает результат "присоединения" второго аргумента в хвост первому.
Если оба аргумента APPEND - списки, то и результат будет списком. Если же второй аргумент - атом,
то в результате получится точечная пара.
Вот примеры работы с функцией APPEND:
(append '(a b c) 'd) ==> (a b c . d) (append 'd 'g) Аргумент CAR - атом (d) ==> ERRSTATE (append '(1 2 3) '(a b c)) ==> (1 2 3 a b c) |
Видно, что функция не работает, если первый аргумент - атом.
|
|
ASSOC |
Функция ASSOC выбирает из ассоциативного списка, заданного вторым аргументом, первую пару, в которой первый элемент совпадает со значением первого аргумента. Как известно, ассоциативный список представляет собой список пар.
Каждый элемент ассоциативного списка - есть точеная пара (в частности - список).
Вот примеры работы с функцией ASSOC :
(assoc 'c '((a . 1) (b . 2) (c . 3) (d . 4))) ==> (c . 3) (assoc 'b '((a . 1) (b . 2) (c . 3) (d . 4))) ==> (b . 2) (assoc 'q '((a . 1) (b . 2) (c . 3) (d . 4))) ==> NIL (assoc 's '((a b c d) (s d f g) (1 2 3 4))) ==> (s d f g) (assoc 1 '((a b c d) (s d f g) (1 2 3 4))) ==> (1 2 3 4) |
В двух последних примерах ассоциативный список представляет собой список списков. Поиск осуществляется путем сравнения значения первого аргумента с головами списков, входящих в ассоциативный список.
|
|
ATOMLIST |
Функция ATOMLIST возвращает Т, если значение аргумента есть список, составленный из атомов,
в противном случае возвращает Nil. В частности, если значение аргумента есть точечная пара, составленная
из атомов, результат тоже будет Nil.
Вот примеры работы с функцией ATOMLIST:
(atomlist '(1 2 3)) ==> T (atomlist '(1 2 (3))) ==> NIL (atomlist '(a . b)) ==> NIL |
|
|
ATTACH |
Функция ATTACH объединяет значения двух своих аргументов в точечную пару (аналогично CONS),
но результат присваивается в качестве значения значению второго аргумента. Функции, которые не только возвращают
значения, но и меняют состояние других объектов программы, называются функциями с побочным эффектом.
Таким образом, ATTACH - функция с побочным эффектом.
Вот примеры работы с функцией ATTACH:
(setq c '(1 2 3)) ==> (1 2 3) (attach 'a c) ==> (a 1 2 3) c ==> (a 1 2 3) (setq z '(q w e)) ==> (q w e) (attach '(1 2) (cdr z)) ==> ((1 2) w e) z ==> (q (1 2) w e) |
Видно, что первый вызова ATTACH приводит к тому, переменная c меняет свое значение. В последнем случае вызова ATTACH переменная z меняет свое значение таким образом, чтобы (cdr z) был бы равен результату ((1 2) w e).
|
|
CART |
Функция CART строит лексикографически упорядоченный список, элементами
которого являются всевозможные двухэлементные списки, первый элемент которых
входит в первый аргумент, а второй элемент - во второй аргумент.
Вот примеры работы с функцией CART :
(cart '(a b c) '(1 2 3)) ==> ((a 1) (a 2) (a 3) (b 1) (b 2) (b 3) (c 1) (c 2) (c 3)) (cart '(a b c) '(1 2 3 4)) ==> ((a 1) (a 2) (a 3) (a 4) (b 1) (b 2) (b 3) (b 4) (c 1) (c 2) (c 3) (c 4)) |
Длина результата функции CART равна произведению длин сомножителей (на верхнем уровне).
|
|
COLLECT |
Функция COLLECT перегруппировывает элементы списка-аргумента таким образом, чтобы одинаковые элементы стояли подряд.
Вот примеры работы с функцией COLLECT :
(collect '(a b c d e f a b c d e f)) ==> (a a b b c c d d e e f f) (collect '((a b) (c d) (a b))) ==> ((a b) (a b) (c d)) (collect '(a b c d e f a b c d e f (a b) (c d) (a b))) ==> (a a b b c c d d e e f f (a b) (a b) (c d)) |
Видно, что функция COLLECT перегруппировывает списки, состоящие не только из атомов, но и из списков.
|
|
COPY |
Функция COPY создает в списочной памяти копию (второй экземпляр) своего аргумента. Эта функция может
быть полезна в случае, когда исходный список требуется подвергнуть разрушающему преобразованию с помощью
функций RPLACA/RPLACD.
Вот примеры работы с функцией COPY :
(setq z1 '(a b c)) ==> (a b c) (setq z2 z1) ==> (a b c) z1 ==> (a b c) z2 ==> (a b c) (rplaca z1 'd) ==> (d b c) z1 ==> (d b c) (rplaca z2 'd) ==> (d b c) (setq z1 '(a b c)) ==> (a b c) (setq z2 (copy z1)) ==> (a b c) (rplaca z1 'd) ==> (d b c) z1 ==> (d b c) z2 ==> (a b c) |
В этом примере происходит следующее: заводится переменная z1 со значением (a b c). Затем
переменной z2 присваивается значение z1. Можно убедиться, что значением обеих
переменных z1 и z2 будет один и тот же список (a b c). Если
с помощью функции RPLACA заменить у значения переменной z1 голову списка с a на
d, то изменят значения обе переменные z1 и z2.
Совсем по-другому будет обстоять дело в том случае, если переменной z2 присвоить значением
копию значения переменной z1: теперь изменение головы списка-значения z1
не окажет никакого влияния на значение z2.
Следует отметить, что функция COPY неприменима к циклическим списочным структурам (выполнение
вызовет зацикливание). Кроме того, если у значения аргумента есть цепочки указателей, сходящиеся к
какой-либо одной структуре, то у результата таких цепочек не будет.
|
|
CYCLEP |
Функция CYCLEP проверяет наличие в списке циклических структур. При наличии циклической
структуры функция возвращает T, при отсутствии - Nil.
Вот примеры работы с функцией CYCLEP:
(setq z '(a b c))
==> (a b c)
(cyclep z)
==> NIL
(rplaca (cddr z) z)
==> ((a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
...)))))))))))))))))))))))))))))))))))))))))
))))))))))))))))))))))))))))))))))))))))))))
))))))))))))))))))))))))))))))))))))))))))))
)))))))))))))))))))))))))))))
(cyclep z)
==> T
|
Здесь сначала создан список (a b c). Он, естественно, не содержит циклов. Поэтому вызов CYCLEP возвращает Nil. Далее с помощью функции RPLACA список превращается в циклическую структуру. Печать таких структур должна выполняться бесконечное время. HomeLisp прекращает печать после вывода определенного количества атомов и ставит многоточие. Вызов CYCLEP c циклической структурой возвращает T - функция работает.
|
|
DEFINE |
Функция DEFINE предназначена для массового определения функций класса EXPR.
Она принимает один параметр, представляющий собой список вида ((F1 O1) (F2 O2)...),
где Fi - имя i-й функции, а Oi - ее определяющее выражение. При успешном завершении
функция создает заданные функции и возвращает список их имен (F1 F2 ...).
Вот примеры работы с функцией DEFINE :
(define ((квадрат (lambda (x) (* x x))) (куб (lambda (x) (* x x x))))) ==> (квадрат куб) (квадрат 7) ==> 49 (куб 5) ==> 125 |
Естественно, что все задаваемые функции могут иметь разные количества аргументов. Важно лишь, что посредством DEFINE можно задать только функцию класса EXPR. Сама функция DEFINE по вполне понятным причинам принадлежит классу FEXPR.
|
|
DEFLIST |
Функция DEFLIST предназначена для маcсового занесения информации в списки свойств атомов.
Функция требует два аргумента: первый из них должен быть списком вида ((A1 P1) (A2 P2)...),
а второй должен быть атомом. Успешное завершение этой функции приводит к тому, что у атома Ai
в списке свойств появляется свойство Pi под индикатором, заданным вторым аргументом DEFLIST.
Функция возвращает список (A1 A2 ...).
Вот примеры работы с функцией DEFLIST, наглядно объясняющий сказанное выше:
(deflist ((a1 красный) (a2 синий) (a3 зеленый)) цвет) ==> (a1 a2 a3) (proplist 'a1) ==> (цвет красный) (proplist 'a2) ==> (цвет синий) (proplist 'a3) ==> (цвет зеленый) |
Если у одного из атомов, список свойств которых модифицируется функцией DEFLIST, уже имеется какое-либо свойство с заданным при вызове DEFLIST индиактором, то свойство замещается новым (из списка DEFLIST).
|
|
DIFLIST |
Функция DIFLIST возвращает спискок, состоящий из тех элементов значения первого аргумента,
которые не входят в список - значение второго аргумента (теоретико-множественная разность). Оба аргумента
функции DIFLIST должны быть списками.
Вот примеры работы с функцией DIFLIST :
(diflist '(a b c) '(a c)) ==> (b) (diflist '(a b c) '(a b c)) ==> NIL (diflist '((a b) c) '(a b c)) ==> ((a b)) (diflist '((a b) c) '((a b) c)) ==> NIL |
Третий и четвертый примеры показывают, что элементы списков, подваемых на вход DIFLIST не обязаны быть атомами, - функция не теряет работспособности, даже если элементы этих списков, в свою очередь, являются списками.
|
|
DPAIR |
Функция DPAIR (как и функция PAIR) объединяет значения двух своих аргументов
в ассоциативный список. При этом, значение первого аргумента заменяется результатом
выполнения функции.
Вот примеры работы с функцией DPAIR:
(setq z1 '(a b c d)) ==> (a b c d) (setq z2 '(1 2 3 4)) ==> (1 2 3 4) (pair z1 z2) ==> ((a . 1) (b . 2) (c . 3) (d . 4)) z1 ==> (a b c d) (dpair z1 z2) ==> ((a . 1) (b . 2) (c . 3) (d . 4)) z1 ==> ((a . 1) (b . 2) (c . 3) (d . 4)) |
Здесь переменным z1 и z2 присвоены четырехэлементные атомарные списки. Вызов функции (pair z1 z2) приводит к образованию ассоциативного списка (списка точечных пар). При этом значение переменной z1 остается прежним. А при вызове (dpair z1 z2) результат получается точно таким же, но значение переменной z1 меняется.
|
|
DREMOVE |
Функция DREMOVE принимает два аргумента. Второй аргумент должен быть списком. Функция
исключает из значения второго аргумента все элементы, совпадающие со значением первого аргумента.
Вот примеры работы с функцией DREMOVE:
(dremove 2 '(1 2 3)) ==> (1 3) (dremove 2 '(2 2 2)) ==> NIL (dremove '(2 3) '(1 2 3 (2 3))) ==> (1 2 3) (dremove '(2 . 3) '(1 2 3 (2 3) (2 . 3) (2 . 3) (2 . 3))) ==> (1 2 3 (2 3)) |
В последних примерах продемонстрировано, что функция исключает не только атомы, но и любые S-выражения.
|
|
DREVERSE |
Функция DREVERSE выполняет оборачивание списка на всех уровнях (аналогично функции REVERSE).
Разница заключается в том, что DREVERSE разрушает значение своего аргумента.
Вот примеры работы с функцией DREVERSE:
(setq z1 '(1 2 3 4)) ==> (1 2 3 4) (reverse z1) ==> (4 3 2 1) z1 ==> (1 2 3 4) (dreverse z1) ==> (4 3 2 1) z1 ==> (1) |
Здесь переменной z1 присваивается значение (1 2 3 4). Применение REVERSE обращает список, но значение z1 остается прежним. А применение DREVERSE тоже обращает список, но значение z1 меняется.
|
|
EFFACE |
Функция EFFACE принимает два аргумента. Второй аргумент должен быть списком, а первый может
быть произвольным S-выражением. Функция исключает из значения второго аргумента первый элемент,
совпадающий со значением первого аргумента. Значением функции является преобразованный список. Если
удаленный элемент стоит не на первом месте в списке-значении второго аргумента, то значением
второго аргумента становится преобразованный список.
Вот примеры работы с функцией EFFACE :
(setq z1 '(1 2 3 4)) ==> (1 2 3 4) (efface 1 z1) ==> (2 3 4) z1 ==> (1 2 3 4) (efface 2 z1) ==> (1 3 4) z1 ==> (1 3 4) |
Переменной z1 присвоено значение (1 2 3 4). Удаление из этого списка элемента 1 не меняет значение переменной z1. Удаление из этого же списка элемента 2 приводит к изменению значения переменной z1.
|
|
EQUAL |
Функция EQUAL (в отличие от встроенной функции EQ) сравнивает два произвольных S-выражения на
идентичность. Функция возвращает T, если выражения идентичны и Nil в противном случае.
Вот примеры работы с функцией EQUAL :
(equal '(1 2 3) '(1 2 3)) ==> T (equal '(1 2 3) '(1 (2) 3)) ==> NIL (equal '(1 (2) 3) '(1 (2) 3)) ==> T (equal '(a . b) '(a . b)) ==> T (setq z '(a . b)) ==> (a . b) (equal '(a . b) z) ==> T |
Видно, что функция корректно работает не только для списков, но и для точечных пар.
|
|
EQUALSET |
Функция EQUALSET проверяет, совпадают ли множества, заданные значениями первого
и второго аргументов. При совпадении функция возвращает T, при несовпадении - Nil.
Вот примеры работы с функцией EQUALSET :
(equalset '(1 2 3) '(3 2 1)) ==> T (equalset '(1 2 3) '(3 2)) ==> NIL |
|
|
FIRST |
Функция FIRST принимает два аргумента (значения которых должны быть списками). Функция выбирает
из элентов, составляющих значение первого аргумента, тот элемент, который раньше других встречается
в списке-значении второго аргумента. Если же не один элемент первого списка не содержится во втором списке,
то функция возвращает первый элемент первого списка.
Вот примеры работы с функцией FIRST :
(first '(1 2 3 4) '(a 3 b 1)) ==> 3 (first '(1 2 3 4) '(a b c)) ==> 1 |
При первом вызове возвращается 3, поскольку в списке (a 3 b 1) тройка встречается раньше единицы.
|
|
FLAG |
Функция FLAG требует два аргумента. Значение первого аргумента должно быть списком атомов.
Функция помещает в список свойств каждого атома первого списка флаг, заданный вторым аргументом.
В качестве значения функция возвращает Nil.
Вот примеры работы с функцией FLAG:
(flag '(a b c) 'цвет) ==> NIL (proplist 'a) ==> (цвет) (proplist 'b) ==> (цвет) (proplist 'c) ==> (цвет) (flag '((a b) (c d)) 're) Аргумент PROPLIST - не атом ==> ERRSTATE (flag '(a b c d) '(re)) ==> NIL (proplist 'a) ==> ((re) цвет) (flag '(a b c) 'цвет) ==> NIL (proplist 'a) ==> ((re) цвет) |
Перый вызов заносит в список свойств атомов a, b и с флаг цвет. Последующие вызовы функции PROPLIST показывают, что занесение успешно. В случае, когда первый аргумент не есть атомарный список, возникает ошибка. Видно также, что при добавлении новых флагов, старые флаги не уничтожаются. Если при добавлении флага выясняется, что такой флаг уже имеется, то удвоение флагов не происходит.
|
|
FLAGP |
Функция FLAGP является предикатом, проверяющим, содержится ли в списке свойств атома,
заданного значением первого аргумента, флаг, заданный значением второго аргумента.
Вот примеры работы с функцией FLAGP:
(flag '(a) 'цвет) ==> NIL (flagp 'a 'цвет) ==> T (flagp 'a 'звук) ==> NIL |
У атома a в список свойств занесен индикатор цвет, но не занесен индикатор звук. Функция FLAGP успешно это демонстрирует.
|
|
FLATTEN |
Функция FLATTEN устраняет у произвольного списка скобочную структуру, перенося все атомы списка на
один уровень (делая список "плоским").
Вот примеры работы с функцией FLATTEN:
(flatten '((a b) (c d) (e f))) ==> (a b c d e f) (flatten '((a . b) (c . d) (e . f))) ==> (a b c d e f) |
Как можно убедиться, функция вполне успешно применима к спискам, состоящим и из точечных пар.
|
|
FOR |
Макро FOR - это простая реализация оператора цикла. Макро требует четыре параметра.
Первый параметр задает параметр цикла; он должен быть атомом. Второй параметр задает
начальное значение параметра цикла, а третий - конечное значение. Шаг цикла всегда равен
1. Четвертый параметр задает тело цикла. Тело цикла представляет собой список
вызовов произвольных функций. Выполнение макро заключается в циклическом повторении
тела цикла при значениях параметра цикла от начального до конечного.
Вот примеры работы с функцией FOR :
(for i 1 10 ((print 'i=)(printline i)))
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
i=10
==> 10
(setq s 0)
==> 0
(for i 1 10 ((setq s (+ s i))))
==> 10
s
==> 55
(macroexpand for i 1 10 ((setq s (+ s i))))
==> (PROG NIL (SETQ i 1)
beg_loop (SETQ s (+ s i))
(SETQ i (ADD1 i))
(COND ((GREATERP i 10) (RETURN 10)))
(GO beg_loop))
|
В первом примере показана простая печать значений переменной цикла. Далее заводится переменная s и ей присваивается значение 0. Затем в цикле в этой переменной накапливается сумма чисел от единицы до десяти (получается 55). Далее показывается, какая PROG-конструкция выполняется на самом деле. Следует обратить внимание на то, что метки локализуются в теле PROG, поэтому макро FOR можно использовать для организации вложенных циклов (а вот параметры вложенных циклов, разумеется, не могут совпадать!)
|
|
FORALL |
Функционал FORALL последовательно применяет свой второй (функциональный) аргумент к элементам списка,
заданного значением первого аргумента. Если результат применения во всех случаях равен T, то возвращается
результат T. В противном случае возвращается результат Nil.
Вот примеры работы с функцией FORALL:
(forall '(1 3 5 7) (function (lambda (x)
(cond ((= (% x 2) 1) T)
(T nil)))))
==> T
(forall '(1 3 5 7 8) (function (lambda (x)
(cond ((= (% x 2) 1) T)
(T nil)))))
==> NIL
(forall '(1 3 4 5 7) (function (lambda (x)
(cond ((= (% x 2) 1) T)
(T nil)))))
==> NIL
|
Здесь при первом вызове проверяется на нечетность каждого элемента список (1 3 5 7). Результат, естественно, равен T. Введение в список четного числа (в любой позиции) меняет результат на Nil.
|
|
FORODD |
Функционал FORODD применяет второй (функциональный) аргумент к элементам списка,
заданным значением первого аргумента. Если результат применения равен T для
нечетного количества элементов, то FORODD возвращает T, в
противном случае - Nil.
Вот примеры работы с функцией FORODD :
(forodd '(1 3 5 7) (function (lambda (x)
(cond ((= (% x 2) 1) T)
(T nil)))))
==> NIL
(forodd '(1 3 5 8) (function (lambda (x)
(cond ((= (% x 2) 1) T)
(T nil)))))
==> T
|
Здесь функциональный аргумент проверяет нечетность очередного элемента списка. Поскольку в первом вызове количество нечетных чисел равно четырем, функция возвращает Nil. Во втором вызове количество нечетных чисел равно трем (нечетное), поэтому результа равен T.
|
|
FORSOME |
Функционал FORSOME применяет свой второй функциональный аргумент
к элементам списка, заданным значением первого аргумента. Если хотя бы для
одного элемента значение оказывается равным T, функция возвращает T;
в противном случае результат будет Nil.
Вот примеры работы с функцией FORSOME:
(forsome '((a b) (c d) (e f)) (function atom)) ==> NIL (forsome '((a b) (c d) e f) (function atom)) ==> T |
В первом случае к элементам неатомарного списка применяется функция ATOM. Поскольку все элементы списка не являются атомами, то FORSOME возвращает Nil. Во втором случае в списке встречаются атомы, поэтому результат равен T.
|
|
GETPROP |
Функция GETPROP извлекает из списка свойств атома, задаваемого значением первого аргумента
свойство, заданное значением второго аргумента. Если такое свойство отсутствует в списке свойств, -
функция возвращает Nil.
Вот примеры работы с функцией GETPROP:
(spropl 'a '(цвет красный звук громкий)) ==> (цвет красный звук громкий) (getprop 'a 'цвет) ==> красный (getprop 'a 'звук) ==> громкий (getprop 'a 'место) ==> NIL |
Здесь в список свойств атома a заносится свойство цвет со значением красный и свойство звук со значением громкий. Далее, вызов GETPROP успешно излекает из списка свойств атома a значения свойств цвет и звук. Попытка извлечь значение свойства место возвращает Nil, поскольку такого свойства у атома a нет. Кстати, отсюда следует что крайне нежелательно использовать атом Nil, как значение свойства: не имеется возможности различать случай отсутствия свойства и наличия свойства Nil.
|
|
INTERSECTION |
Функция INTERSECTION требует два аргумента. Оба должны быть списками. Функция возвращает
список, состоящий из элементов, входящих в оба списка (теоретико-множественное пересечение).
Вот примеры работы с функцией INTERSECTION:
(intersection '(1 2 3 4 5 6) '(3 5 7)) ==> (3 5) (intersection '((1 2) (3 4) 5 6) '(3 5)) ==> (5) |
Во втором случае общим элементом, входящим в оба списка будет только атом 5.
|
|
LAST |
Функция LAST принимает один аргумент, значение которого должно быть списком.
Функция возвращает последний элемент этого списка (на верхнем уровне списка).
Вот примеры работы с функцией LAST:
(last '(a b)) ==> b (last '(a)) ==> a (last '(a (b c))) ==> (b c) |
У списка (a (b c)) последний элемент на верхнем уровне - это список (b c), а не атом c, как могло бы показаться.
|
|
LCYCLEP |
Функция LCYCLEP проверяет значение своего аргумента на наличие циклов по цепочке d-указателей.
Если циклы имеются - функция возвращает T, в противном случае - Nil.
Вот примеры работы с функцией LCYCLEP :
(setq z '(a b c))
==> (a b c)
(lcyclep z)
==> Nil
(rplacd (cddr z) z)
==> (c a b c a b c a b c a b c a b c a b c a b c
a b c a b c a b c a b c a b c a b c a b c a
b c a b c a b c a b c a b c a b c a b c a b
c a b c a b c a b c a b c a b c a b c a b c
...)
(cyclep z)
==> T
(lcyclep z)
==> T
(setq z '(a b c))
==> (a b c)
(rplaca (cddr z) z)
==> ((a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b
(a b (a b (a b (a b (a b (a b (a b (a b (a b ...
))))))))))))))))))))))))))))))))))))))))))))))))
(cyclep z)
==> T
(lcyclep z)
==> NIL
|
В обоих случаях за основу берется линейный список (a b c). В первом случае он "зацикливается" по d-указателю. Вычисление предикатов CYCLEP и LCYCLEP дает в результате T. Во втром случае "зацикливание" выполняется по a-указателю. Предикат CYCLEP дает при вычислении T (циклы есть), а предикат LCYCLEP возвращает Nil - циклов по d-указателю нет.
|
|
LENGTH |
Функция LENGTH определяет длину списка (количество элементов) на верхнем уровне. Следует отметить,
что значение единственного аргумента функции LENGTH должно быть списком. Для точечной пары
функция возвращает неправильный результат. Если же значение аргумента - атом, то функция вернет нуль.
Вот примеры работы с функцией LENGTH :
(length '(q w e r t y)) ==> 6 (length '(q (w e r t y))) ==> 2 (length '(a . b)) ==> 1 (length 'a) ==> 0 |
Во втором случае на вход функции подан двухэлементный список: первый элемент - атом q, а второй - список (w e r t y). Поэтому функция LENGTH возвращает 2.
|
|
LEXORDER |
Функция LEXORDER принимает три аргумента. Значения аргументов должны быть списками. Функция сравнивает
попарно первые два списка (первый элемент с первым, второй - со вторым, и т.д.). Сравниваются только различные атомы
с помощью функции ORDER1. В качестве упорядочивающего списка используется
значение третьего аргумента.
Результат сравнения (T, Nil или ORDERUNDEF) выдается
в качестве результата. Если раньше, чем встретятся различные элементы, исчерпается
первый список, то функция вернет T. Если же раньше исчерпается второй список, то функция вернет Nil.
Вот примеры работы с функцией LEXORDER:
(lexorder '(a b c) '(d e f) '(a b c d e f)) ==> T (lexorder '(a b c) '(a b) '(a b c d e f)) ==> NIL (lexorder '(a b) '(a b c) '(a b c d e f)) ==> T (lexorder '(b a) '(a b c) '(a b c d e f)) ==> NIL (lexorder '(g b) '(z b c) '(a b c d e f)) ==> orderundef |
В первом случае атомы пары a и d стоят в правильном порядке, поэтому результат равен T. Во втором случае раньше исчерпался второй список - результат Nil. В третьем случае раньше исчерпался первый список - результат T. В следующем случае первая пара атомов b и a стоит в "неправильном" порядке - результат Nil. И, наконец, в последнем случае атомы g и z отсутствуют в упорядочивающем списке, поэтому функция возвращает ORDERUNDEF.
|
|
LEXORDER1 |
Функция LEXORDER1 работает аналогично описанной выше функции LEXORDER, за одним
существенным исключением: значением третьего аргумента должен быть список, состоящий из списков, а не атомов.
Когда выполняется сравнение i-й пары атомов, то в качестве упорядочивающего используется i-й
элемент значения третьего аргумента.
Вот примеры работы с функцией LEXORDER1 :
(lexorder1 '(b c) '(d e) '((d b u v) (a b c d))) ==> NIL (lexorder1 '(a b c) '(a d e) '((a b c d) (b d u v)) (1 2 3)) ==> T (lexorder1 '(a b w) '(a b z) '((a b c d) (1 2 3) (b d u v))) ==> orderundef |
Первый вызов возвращает Nil, поскольку пара атомов b и d стоит в "неправильном" порядке. Второй вызов возвращает T, поскольку пара атомов b и d стоит в "правильном" порядке. В третьем вызове оба атома w и z отсутствуют в управляющем списке (b d u v), поэтому результат равен ORDERUNDEF.
|
|
LISTP |
Функция LISTP применяется к произвольному S-выражению. Она возвращает T, если выражение
есть список (т.е. может быть изображено без точек). В противном случае (когда значение аргумента есть
атом или точечная пара, которую нельзя изобразить без точек), - функция возвращает Nil.
Вот примеры работы с функцией LISTP :
(listp 'a) ==> NIL (listp '(a)) ==> T (listp '(a . b)) ==> NIL (listp '((a . b) (c . d))) ==> NIL (listp '(a.b)) ==> T |
Комментария требует последний вызов. Дело в том, что конструкция a.b есть атом, поскольку отсутствуют пробелы между точкой и буквами. Поэтому (a.b) есть список, отсюда и результат - T.
|
|
LUNION |
Функция LUNION принимает один аргумент, значение которого должно быть списком списков.
Функция строит список, являющийся теоретико-множественным объединением элементов, входящих
в списки, из которых состоит значение аргумента.
Вот примеры работы с функцией LUNION:
(lunion '(1 1 1 2 2 3 3 3 3)) Аргумент CAR - атом (3) ==> ERRSTATE (lunion '((1 1) (1 2) (2 3) (3 3 3))) ==> (2 3 1) (lunion '((a b) (c d) ((a b) c c) (d d d))) ==> (b a c (a b) d) |
Первый (ошибочный!) вызов показывает разницу между функцией LUNION и MAKESET, описанной ниже: список, подаваемый на вход LUNION должен состоять из списков, а не из атомов. Два других вызова показывают, как LUNION строит объединение множеств.
|
|
MAKESET |
Функция MAKESET требует единственный аргумент, значение которого может быть произвольным
списком. Функция строит и возвращает в качестве значения новый список, в котором элементы, входящие
в исходный список, содержатся в единственном экземпляре. Другими словами, MAKESET строит
множество элементов, из которых состоит значение аргумента.
Вот примеры работы с функцией MAKESET:
(makeset '(1 1 1 2 2 2 3 3 3 3)) ==> (3 2 1) (makeset '(1 1 1 2 2 2 (3) 3 3 3)) ==> (3 (3) 2 1) (makeset '(1 1 1 2 2 2 (3) (3) 3 3)) ==> (3 (3) 2 1) |
Важно подчеркнуть, что даже если некий элемент входит в исходный список более одного раза, в выходной список он попадет в единственном экземпляре.
|
|
MAP |
Функционал MAP принимает два аргумента: произвольный список и функциональное выражение.
Функциональный аргумент последовательно применяется к значению первого аргумента, к значению
первого аргумента без первого элемента, без второго элемента и т.д. до исчерпания списка.
Функционал MAP всегда возвращает Nil; он похож по действию на функционал MAPLIST,
но его имеет смысл использовать в случае, когда функциональный аргумент вызывается только ради побочного
эффекта (например, ради печати какой-либо информации).
Вот примеры работы с функцией MAP:
(map '(1 2 3 4 5 6 7) (function (lambda (x)
(printline (eval (cons '+ x))))))
28
27
25
22
18
13
7
==> NIL
|
В этом примере функциональный аргумент принимает на вход список чисел, "приклеивает" к началу знак плюс, вычисляет и печатает значение полученной формы (т.е. сумму чисел). Сначала вычисляется форма (+ 1 2 3 4 5 6 7) - печатается 28; затем функциональный аргумент применяется к остатку исходного списка без первого элемента, т.е. вычисляется форма (+ 2 3 4 5 6 7) - печатается 27 и т.д.
|
|
MAPCAR |
Функция MAPCAR принимает два аргумента: произвольный список и функциональное выражение.
Функциональный аргумент применяется последовательно к каждому элементу, составляющему значение
первого аргумента. Из получаемых значений строится список, который и возвращается, как
результат вычисления функции.
Вот примеры работы с функцией MAPCAR :
(mapcar '(1 2 3 4 5 6 7 8) (function fact))
==> (1 2 6 24 120 720 5040 40320)
(mapcar '(1 2 3 4 5 6 7 8) (function (lambda (x)
(cond ((= (% x 2) 0) 'Чет)
(T 'Нечет)))))
==> (Нечет Чет Нечет Чет Нечет Чет Нечет Чет)
|
В первом примере функциональный аргумент задан функцией fact, вычисляющей факториал своего аргумента. Легко видеть, что результат MAPCAR в этом случае предствляет собой список факториалов чисел, составляющих исходный список. Во втором примере функциональный аргумент задан лямбда-выражением, которое проверяет значение аргумента на четность. Исходный список заменяется списком атомов Чет и Нечет (в зависмости от того четно или нечетно очередное число исходного списка).
|
|
MAPLIST |
Функционал MAPLIST применяет свой второй (функциональный) аргумент к значению первого аргумента,
и ко всем спискам, получающимся из значения первого аргумента отбрасыванием головы списка. Результаты
вычисления объединяются в список, который возвращается в качестве результата.
Вот примеры работы с функцией MAPLIST:
(maplist '(1 2 3 4 5 6 7) (function (lambda (x)
(eval (cons '+ x)))))
==> (28 27 25 22 18 13 7)
|
В качестве функционального аргумента задана функция, вычисляющая сумму числового списка. Применение MAPLIST возвращает список, состоящий из сумм: всего исходного списка, исходного списка без первого элемента, без двух первых и т.д.
|
|
MEMB |
Функция MEMB требует два аргумента. Первый аргумент должен быть атомом, а второй - списком.
Функция проверяет, входит ли значение первого аргумента в список, заданный вторым аргументом.
Если входит - MEMB возвращает T, иначе Nil.
Вот примеры работы с функцией MEMB:
(memb 1 '(1 2 3 4)) ==> T (memb 5 '(1 2 3 4)) ==> NIL (memb '(5) '(1 2 3 4 (5))) ==> NIL |
Последний пример показывает, что если первый аргумент - не атом, функция не возвращает ошибки, но работает некорректно. Более широкой областью применения обладает функция MEMBER, описываемая ниже.
|
|
MEMBER |
Функция MEMBER принимает два аргумента, оба могут быть списками. Функция проверяет, входит
ли список, заданный первым аргументом, в список, заданный вторым аргументом. Если это так, функция
возвращает T, а иначе - Nil.
Вот примеры работы с функцией MEMBER:
(member '(5) '(1 2 3 (5) 4)) ==> T (member '(6) '(1 2 3 (5) 4)) ==> NIL |
|
|
NCONC |
Функция NCONC принимает два аргумента, значениями которых должны быть списки.
Функция "склеивает" списки-аргументы в единый список (выполняя то же действие, что и
APPEND. Отличие состоит в том, что NCONC имеет
побочный эффект - присваивает значение результата первому аргументу.
Вот примеры работы с функцией NCONC :
(setq z1 '(1 2 3)) ==> (1 2 3) (setq z2 '(4 5 6)) ==> (4 5 6) (nconc z1 z2) ==> (1 2 3 4 5 6) z1 ==> (1 2 3 4 5 6) |
Значение переменной z1 изменилось (чего не было бы при использовании функции APPEND).
|
|
ORDER |
Функция ORDER принимает три аргумента: значения первых двух должны быть атомами, а третьего - списком (будем называть его упорядочивающим списком).
Функция проверяет, встречаются ли атомы, заданные первым и вторым аргументами, в списке, заданном третьим аргументом в заданном порядке (в этом случае результат будет T, в противном случае - Nil).
Вот примеры работы с функцией ORDER:
(order 'f 'g '(a b c d e f g h)) ==> T (order 'g 'f '(a b c d e f g h)) ==> NIL (order 'g 'g '(a b c d e f g h)) ==> T (order 'f 'g '(a b c d)) ==> NIL (order 'f 'z '(a b c d e f g h)) ==> T (order 'z 'h '(a b c d e f g h)) ==> NIL |
В первом вызове атомы f и g встречаются в упорядочивающем списке в "правильном"
порядке. Функция возвращает T. Во втром вызове атомы f и g встречаются "неправильном"
порядке. Функция возвращает Nil. В третьем случае атомы f и g вообще не встречаются в
упорядочивающем списке. В этом случае функция возвращает Nil, что неудобно (поскольку нет возможности
отличить неверный порядок от отсутствия атомов в списке). Этого недостатка лишена функция ORDER1,
описываемая ниже.
Следующие два вызова показывают, что если первый из атомом найден в упорядочивающем списке, а второй - нет,
то функция возвращает T. А если первый атом не найден, а второй найден - результат будет Nil.
|
|
ORDER1 |
Функция ORDER1 (как и описанная выше функция ORDER) принимает три аргумента: значения первых двух должны быть атомами, а третьего - списком (будем называть его упорядочивающим списком).
Функция проверяет, встречаются ли атомы, заданные первым и вторым аргументами, в списке, заданном третьим аргументом в заданном порядке (в этом случае результат будет T, в противном случае - Nil).
Отличие от функции ORDER заключается в том, если оба атома не найдены в упорядочивающем списке, то функция
возвращает не Nil, а специальный атом ORDERUNDEF.
Вот примеры работы с функцией ORDER1 :
(order1 'f 'w '(1 2 3 f g h w)) ==> T (order1 'w 'f '(1 2 3 f g h w)) ==> NIL (order1 'd 'f '(1 2 3 f g h w)) ==> NIL (order1 'd 'z '(1 2 3 f g h w)) ==> orderundef |
В последнем случае оба атома отсутствуют в списке и функция возвращает ORDERUNDEF.
|
|
PAIR |
Функция PAIR строит из двух списков список пар (ассоциативный список). Оба аргумента
функции должны быть списками.
Вот примеры работы с функцией PAIR :
(pair '(a b c d) '(1 2 3 4)) ==> ((a . 1) (b . 2) (c . 3) (d . 4)) (pair '(a b c d e f) '(1 2 3)) ==> ((a . 1) (b . 2) (c . 3) (d) (e) (f)) (pair '(a b c d) '(1 2 3 4 5)) ==> ((a . 1) (b . 2) (c . 3) (d . 4)) |
Если первый список длинее второго, то элементы первого списка, лишенные пар, объединяются с атомом Nil. Если же длиннее второй список, то элементы, лишенные пар, просто отбрасываются.
|
|
PAIRLIS |
Функция PAIRLIS принимает три аргумента (все три должны быть списками). Функция объединяет
значения первых дух аргументов в ассоциативный список и "склеивает" этот список со значением третьего
аргумента. Другими словами, функция добавляет новые пары к существующиему ассоциативному списку (заданному
третьим аргументом).
Вот примеры работы с функцией PAIRLIS:
(pairlis '(a b c) '(1 2 3) '((q . 1) (w . 2) (e . 3))) ==> ((a . 1) (b . 2) (c . 3) (q . 1) (w . 2) (e . 3)) (pairlis '(a b c) '(1 2) '((q . 1) (w . 2) (e . 3))) ==> ((a . 1) (b . 2) (c) (q . 1) (w . 2) (e . 3)) (pairlis '(a b) '(1 2 3) '((q . 1) (w . 2) (e . 3))) ==> ((a . 1) (b . 2) (q . 1) (w . 2) (e . 3)) |
Видно, что функция PAIRLIS объединяет значения первых двух аргументов в точности, описанная выше функция PAIR.
|
|
POP |
Функция POP (также, как и функция PUSH) предназначена для организации
стека. В качестве хранилища используется линейный список. Результат вычисления (POP A) полностью
эквивалентен вычислению (SETQ A (CDR A)) (другими словами, функция имеет побочный эффект).
Вот примеры работы с функцией POP :
(setq Stack '(a b c d)) ==> (a b c d) (pop Stack) ==> (b c d) |
Следует отметить, что хотя функция POP принадлежит классу FEXPR, переменная Stack корректно заменяется своим значением. Но происходит это не до вычисления, а уже в процессе вычисления функции. Функция POP по своему действию немного непохожа на традиционную функцию POP: она убирает со стека верхий элемент, но не возвращает его. Более близкой к традиционной функции является функция POPUP, описываемая ниже.
|
|
POPUP |
Функция POPUP, в отличие от описываемой выше функции POP, не только удаляет
из стека верхний элемент, но и присваивает заданной переменной значение этого элемента. Если переменная
STACK имеет своим значением список, то результат вычисления (POPUP A STACK)
эквивалентен последовательному вычислению двух выражений: (SETQ A (CAR STACK)) и (SETQ STACK (CDR STACK)).
В качестве результата функция возвращает Nil.
Вот примеры работы с функцией POPUP:
(setq stack '(a b c d)) ==> (a b c d) (popup z stack) ==> NIL z ==> a stack ==> (b c d) (popup z stack) ==> NIL z ==> b stack ==> (c d) |
Видно, что каждый вызов POPUP удаляет из списка первый элемент и присваивает его первому аргументу функции POPUP.
|
|
POSSESSING |
Функционал POSSESSING, используя значение второго аргумента (список), строит новый список,
включая в него только те элементы исходного списка, для которого истино значение первого
(функционального) аргумента, вычисленной с очередным элементом исходного списка. Функциональный
аргумент должен задавать функцию одного переменного, возвражающую T или Nil.
Вот примеры работы с функцией POSSESSING:
(possessing (function (lambda (x) (= (% x 2) 0))) '(1 2 3 4 5 6 7 8)) ==> (2 4 6 8) (possessing (function (lambda (x) (= (% x 2) 1))) '(1 2 3 4 5 6 7 8)) ==> (1 3 5 7) (possessing (function (lambda (x) (= (% x 2) 1))) '(2 4 6 8)) ==> NIL |
В первом примере функциональный аргумент "отфильтровывает" четные элементы исходного списка. Во втором - нечетные. А в третьем случае - снова нечетные (и, поскольку список не содержит нечетных элементов, результат равен пустому списку).
|
|
PROP |
Функция PROP принимает три аргумента. Значениями первых двух должны быть атомы. Третий аргумент - функциональный.
Если у атома, заданного первым аргументом, есть свойство, заданное значением
второго аргумента, то функция вернет хвост списка свойств, следующий за найденным индикатором.
Если свойства нет - будет произведен вызов функции, заданной третьим аргументом. Эта функция не должна
принимать параметров.
Вот примеры работы с функцией PROP :
(putprop 'a 'color 'red) ==> a (proplist 'a) ==> (color red) (prop 'a 'place (function (lambda nil (printline "Свойства нет")))) "Свойства нет" ==> "Свойства нет" (prop 'a 'color (function (lambda nil (printline "Свойства нет")))) ==> (red) |
У чистого атома a формируется свойство color со значением red. Вызов списка свойств атома подтверждает успешность формирования. Далее для атома a вызывается функция PROP c запросом свойства place. Поскольку такого свойств нет, вызывается функция, заданная третьим аргументом. Следующий вызов PROP запрашивает свойство color; такое свойство есть, поэтому возвращается хвост списка свойств атома a (после свойства color).
|
|
PUSH |
Функция PUSH вместе с функциями POP и POPUP
предназначена для организации стеков. Результат вычисления (PUSH A1 A2) полностью эквивалентен вычислению
(SETQ A2 (CONS A1 A2)). Другими словами, функция "приклеивает" значение своего первого аргумента к началу
списка, заданного вторым аргументом.
Вот примеры работы с функцией PUSH:
(push 1 stack) *Атом stack не имеет значения (не связан). ==> ERRSTATE (setq stack nil) ==> NIL (push 1 stack) ==> (1) (push 2 stack) ==> (2 1) (push '(3 4) stack) ==> ((3 4) 2 1) |
Первый вызов функции выполнен в предположении, что переменная stack не имеет значения. Хотя функция PUSH принадлежит к классу FEXPR, значения ее аргументов вычисляются (уже в процессе вычисления тела функции). Поэтому первый вызов завершается ошибкой. После присвоения переменной stack значения Nil, функция начинает работать правильно. Последний вызов показывает, что в стек можно помещать не только атомы, но и списки.
|
|
PUTFLAG |
Функция PUTFLAG помещает в список свойств атома, заданного первым аргументом, флаг, заданный значением
второго аргумента. В качестве результата, функция выдает модифицированный список атома, заданного первым аргументом.
Вот примеры работы с функцией PUTFLAG:
(putflag 'a 'color) ==> (color) (putflag 'a 'x) ==> (x color) (putflag 'a 'y) ==> (y x color) (proplist 'a) ==> (y x color) |
Особых комментариев не требуется: видно, что флаги последовательно добавляются в список свойств. Важно отметить, что если добавляемый флаг уже имеется в списке свойств атома, то он добавляется повторно.
|
|
PUTPROP |
Функция PUTPROP принимает три аргумента. Первый аргумент задает, атом, список свойств которого
модифицируется. Второй аргумент задает имя свойства (т.н. индикатор). Третий аргумент (произвольное S-выражение) задает
значение свойства. Функция возвращает в качестве значения атом, список свойств которого подвергается изменениям.
Вот примеры работы с функцией PUTPROP:
(putprop 'a 'x 10) ==> a (putprop 'a 'y 20) ==> a (proplist 'a) ==> (x 10 y 20) (putprop 'a 'y 200) ==> a (proplist 'a) ==> (x 10 y 200) |
В список свойств атома a добавляются два индикатора: x и y. Можно убедиться, что повторное добавление индикатора с другим значением проходит корректно (просто меняется значение индикатора).
|
|
RANK |
Функция RANK принимает два аргумента (значения которых должны быть списками). Функция
упорядочивает значение первого аргумента, используя значение второго, как упорядочивающий список.
Если в первом списке есть элементы, которые не входят в упорядочивающий список, то такие элементы
при упорядочении просто переносятся в конец списка (без изменения относительного расположения).
Вот примеры работы с функцией RANK:
(rank '(b c a a d a c b) '(a b c d)) ==> (a a a b b c c d) (rank '(b c a a d a c b x y z) '(a b c d)) ==> (a a a b b c c d x y z) (rank '(x y z b c a a d a c b) '(a b c d)) ==> (a a a b b c c d x y z) (rank '(z x y z b c a a d a c b) '(a b c d)) ==> (a a a b b c c d z x y z) (rank '(z x y z b c a a d a c b) '((a b) c d)) ==> (c c d z x y z b a a a b) |
Во всех случаях красным цветом выделены атомы, не участвующие в уорядочении.
|
|
REMFLAG |
Функция REMFLAG предназначена для работы со списком свойств атома.
Функция удаляет флаг, заданный значением второго аргумента, из списка свойств каждого из атомов, входящих в список,
заданный первым аргументом.
Вот примеры работы с функцией REMFLAG :
(putflag 'a 'i1) ==> (i1) (putflag 'a 'i2) ==> (i2 i1) (putflag 'a 'i3) ==> (i3 i2 i1) (remflag '(a) 'i1) ==> NIL (proplist 'a) ==> (i3 i2) (remflag '(a) 'i2) ==> NIL (proplist 'a) ==> (i3) (remflag '(a) 'i3) ==> NIL (proplist 'a) ==> NIL |
Здесь в список свойств чистого атома a последовательно заносятся флаги i1, i2 и i3. Затем они удаляются с использованием функции REMFLAG.
|
|
REMOVE |
Функция REMOVE удаляет из списка, заданного значением второго аргумента, все вхождения
значения первого аргумента.
Вот примеры работы с функцией REMOVE:
(remove 'a '(a b c d a a b c d)) ==> (b c d b c d) (remove '(a b) '(a b (a b) c d a (a b) c d)) ==> (a b c d a c d) |
В первом примере из списка (a b c d a a b c d) удаляются все вхождения атома a. Во втором случае из списка (a b (a b) c d a (a b) c d) удаляются все вхождения списка (a b).
|
|
REMOVEF |
Функция REMOVEF похожа на функцию REMOVE, но, в отличие от нее, удаляет
из значения второго аргумента не все вхождения значения первого аргумента, а только первое вхождение.
Если удаляемое значение отсутствует, то список не меняется.
Вот примеры работы с функцией REMOVEF :
(removef 'a '(z a b c d a a b c d)) ==> (z b c d a a b c d) |
Удален только первый атом a, остальные остались на своих местах.
|
|
REMPROP |
Функция REMPROP принимает два аргумента. Значение первого аргумента должно быть атомом.
Функция удаляет из списка свойств этого атома свойство с индикатором, совпадающим со значением второго
аргумента. Если такого индикатора нет в списке свойств то список свойств не меняется.
Функция возвращает в качестве значения атом, список свойств которого подвергается модификации.
Вот примеры работы с функцией REMPROP:
(putprop 'a 'i1 '(x y z)) ==> a (putprop 'a 'i2 '(1 2 3)) ==> a (proplist 'a) ==> (i1 (x y z) i2 (1 2 3)) (remprop 'a 'i1) ==> a (proplist 'a) ==> (i2 (1 2 3)) (remprop 'a 'i3) ==> a (proplist 'a) ==> (i2 (1 2 3)) (remprop 'a 'i2) ==> a (proplist 'a) ==> NIL |
К списку свойств атома a (изначально пустому) добавляются свойства (x y z) под индикатором i1 и (1 2 3) под индикатором i2. Затем с помощью REMPROP удаляется индикатор i1. Последующий вызов PROPLIST показывает, что индикатор и свойство успешно удалены. Далее делается попытка удалить индикатор i3. Поскольку такого индикатора в списке свойств атома a нет, то список свойств не меняется. И, наконец, удаление индикатора i2 очищает список свойств полностью.
|
|
REVERSE |
Функция REVERSE обращает список, заданный значением своего аргумента. Обращение заключается в том,
что элементы списка (на верхнем уровне) перестраиваются в обратном порядке: первый элемент становится последним,
второй - предпоследним и т.д.
Вот примеры работы с функцией REVERSE :
(reverse '(1 2 3 4 5)) ==> (5 4 3 2 1) (reverse '(1 (2 3) 4 5)) ==> (5 4 (2 3) 1) |
Во втором примере видно, что подсписок (2 3) входного списка перемещается на новое место, но не обращается.
|
|
SASSOC |
Функция SASSOC работает аналогично описанной выше функции ASSOC, но
примает третий (функциональный аргумент). Этот функциональный аргумент должен задавать вызов функции без
параметров. Функция будет вызвана, если S-выражение, заданное значением первого аргумента, не будет найдено
в ассоциативном списке, заданным значением второго аргумента.
Вот примеры работы с функцией SASSOC:
(sassoc 'a '((1 . 2) (3 . 4) (a . b) (c . d)) (function (lambda
nil (printsline "не найдено!"))))
==> (a . b)
(sassoc 'w '((1 . 2) (3 . 4) (a . b) (c . d)) (function (lambda
nil (printsline "не найдено!"))))
не найдено!
==> "не найдено!"
|
В первом случае атом a найден в ассоциативном списке. Во втором случае, атом w отсутствует в ассоциативном списке, поэтому вызывается функция, заданная третьим аргументом.
|
|
SELECT |
Функция SELECT принимает три аргумента. Значение первого аргумента - произвольное S-выражение.
Значением второго аргумента должен быть список. Значение третьего аргумента - тоже произвольное S-выражение.
Функция SELECT ищет значение первого аргумента в списке, заданным значением второго аргумента,
на нечетных местах. Если выражение найдено - выдается элемент списка, стоящий на следующем (четном)
месте. Если выражение не найдено - то в качестве значения выдается значение третьего аргумента.
Вот примеры работы с функцией SELECT:
(select 'c '(a 1 b 2 c 3 d 4) 'NotFound) ==> 3 (select 'a '(a 1 b 2 c 3 d 4) 'NotFound) ==> 1 (select 'z '(a 1 b 2 c 3 d 4) 'NotFound) ==> NotFound (select '(b b) '((a a) (1 1) (b b) (2 2) (c c) (3 3)) 'NotFound) ==> (2 2) |
В последнем случае выражение (b b) найдено на третьем месте. А на следующем (четвертом) месте стоит выражение (2 2), - оно и выдается в качестве результата.
|
|
SETOF |
Функция SETOF делает в точности то же самое, что и описанная выше функция MAKESET -
строит список элементов, из которых состоит значение единственного аргумента. Отличие лишь в том, что порядок
следования элементов результата у SETOF обратный.
Вот примеры работы с функцией SETOF:
(makeset '(1 1 1 2 2 2 (3) (3) 3 3)) ==> (3 (3) 2 1) (setof '(1 1 1 2 2 2 (3) (3) 3 3)) ==> (1 2 (3) 3) (makeset '(1 1 1 2 2 2 3 3)) ==> (3 2 1) (setof '(1 1 1 2 2 2 3 3)) ==> (1 2 3) |
|
|
SUBLIS |
Функция SUBLIS принимает два аргумента. Значением первого аргумента должен быть ассоциативный
список (список пар). Значением второго аргумента может быть произвольное S-выражение. Функция берет
каждый атом, входящий в значение второго аргумента, и заменяет его на ассоциацию из ассоциативного
списка, заданного значением первого аргумента. Функция возвращает результат замены.
Вот примеры работы с функцией SUBLIS :
(sublis '((a . 1) (b . 2) (c . 3)) '(a b c)) ==> (1 2 3) (sublis '((a . 1) (b . 2) (c . 3)) '(a . b)) ==> (1 . 2) (sublis '((a . 1) (b . 2) (c . 3)) 'a) ==> 1 (sublis '((a . 1) (b . 2) (c . 3)) '(c a z)) ==> (3 1 z) |
Второй и третий вызовы функции SUBLIS показывают, что на месте второго аргумента может быть не только список, но и атом или точечная пара. Последний вызов показывает, что если для какого-либо атома ассоциация не найдена, то этот атом не заменяется.
|
|
SUBSET |
Если каждый элемент списка, заданного первым аргументом Функции SUBSET , входит в список, заданный
вторым аргументом, то функция возвращает T. В противном случае возвращается Nil. Другими словами,
функция проверяет, является ли множество элементов первого списка подмножеством элементов второго.
Вот примеры работы с функцией SUBSET:
(subset '(1 2 3) '(1 2 3 4 5 6)) ==> T (subset '(1 2 3 8) '(1 2 3 4 5 6)) ==> NIL (subset '(1 2 3 3 2 2 1 1 1) '(1 2 3 4 5 6)) ==> T |
Второй вызов возвращает Nil, поскольку 8 не входит во второй список. Третий пример показыаает, что функция сравнивает множества уникальных элементов. Хотя список (1 2 3 3 2 2 1 1 1) длиннее списка (1 2 3 4 5 6), множество элементов {1 2 3} входит в множество {1 2 3 4 5 6}.
|
|
SUBST |
Функция SUBST выполняет замену в выражении, заданном третьим аргументом все вхождения значения второго
аргумента (на всех уровнях) на значение первого аргумента.
Вот примеры работы с функцией SUBST:
(subst 'a 'b '(a b c)) ==> (a a c) (subst 'b 'a '(a b c)) ==> (b b c) (subst '(1 2) '(a b) '((a b) (c d) (a b))) ==> ((1 2) (c d) (1 2)) |
|
|
SUCHTHAT |
Функционал SUCHTHAT принимает два аргумента. Первый аргумент - функциональный, задающий
вызов функции одного аргумента (будем называть ее проверяющей функцией). Значение второго аргумента SUCHTHAT
должно быть списокм. Функционал SUCHTHAT последовательно
применяет функциональный аргумент к элементам списка, заданного значением второго аргумента,
и возвращает первый элемент списка, для которого значение проверяющей функции истино.
Вот примеры работы с функцией SUCHTHAT :
(suchthat (function (lambda (x) (= (% x 2) 0))) '(1 3 5 6 7 8)) ==> 6 (suchthat (function (lambda (x) (= (% x 2) 1))) '(1 3 5 6 7 8)) ==> 1 (suchthat (function (lambda (x) (= (% x 2) 1))) '(0 3 5 6 7 8)) ==> 3 (suchthat (function atom) '((a b) (c d) e (1 2))) ==> e (suchthat (function listp) '((a b) (c d) e (1 2))) ==> (a b) |
В первом примере функция успешно находит первое четное число. В двух последующих - первое нечетное. В четвертом примере функция находит первый атом, а в пятом - первый список.
|
|
SUCHTHAT1 |
Функционал SUCHTHAT1 принимает четыре аргумента. Первый из них функциональный (задает
проверяющую функцию). Значение второго аргумента задает проверяемый список. Третий и четвертый аргументы
могут быть произвольными S-выражениями. Функционал SUCHTHAT1 последовательно применяет
функциональный аргумент к элементам проверяемого списка. Если хотя бы для одного из этих элементов,
значение проверяющей функции истино, то функционал SUCHTHAT1 возвращает значение своего четвертого
аргумента. Если же для всех элементов проверяемого списка значение проверяющей функции ложно,
то функционал SUCHTHAT1 возвращает значение своего третьего аргумента.
Вот примеры работы с функцией SUCHTHAT1:
(suchthat1 (function listp) '((a b) (c d) e (1 2)) 'нет 'есть) ==> есть (suchthat1 (function listp) '((a . b) (c . d) e (1 . 2)) 'нет 'есть) ==> нет |
В обоих примерах проверяющая фукнкция ищет списки (S-выражения, которые можно изобразить без помощи точек). В первом из приведенных примеров проверяемый список содержит подсписки, потому возвращается атом есть. Во втором случае все элементы проверяемого списка - либо точечные пары, либо атомы; возвращается атом нет.
|
|
SUCHTHAT2 |
Функционал SUCHTHAT2 принимает три аргумента. Первый аргумент задает проверяющую функцию. Второй -
проверяемый список. Третий аргумент, также, как и первый - функциональный. Проверяющая функция
последовательно применяется к элементам проверяемого списка. Как только значение проверяющей функции
оказывается истиным, к остатку списка, начиная с этого элемента, применяется третий аргумент. Результат
применения третьего аргумента к остатку проверяемого списка и возвращается в качестве результата функционал SUCHTHAT2.
Если значение проверяющей функции ложно для всех элементов проверяемого списка, то функционал SUCHTHAT2
возвращает Nil.
Вот примеры работы с функцией SUCHTHAT2:
(suchthat2 (function atom) '((1 2) (3 4) 5 6 7 8) (function sumlist)) ==> 26 (suchthat2 (function atom) '((1 2) (3 4) (5 6) (7 8)) (function sumlist)) ==> NIL |
Выполняется суммирование хвоста списка, начиная с первого атома. В первом примере список содержит атомы, а во втором - нет.
|
|
TCONC |
Следуя Лаврову и Силагадзе, будем называть очередью структуру,
состоящую из списка и ячейки, хранящей указатель на первый и последний элементы списка.
Графически очередь может быть представлена следующим образом:
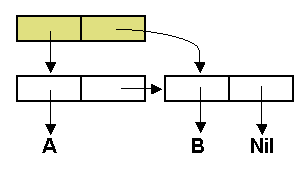
Функция TCONC предназначена для работы с очередью: она помещает значение своего
первого аргумента в очередь, заданную значением второго аргумента.
Вот примеры работы с функцией TCONC :
(setq que Nil) ==> NIL (tconc 'a que) ==> ((a) a) (tconc 'b que) ==> ((b) b) (setq que (tconc 'a que)) ==> ((a) a) (setq que (tconc 'b que)) ==> ((a b) b) (setq que (tconc 'c que)) ==> ((a b c) c) |
Сначала переменной que присваивается значение Nil. Следующий вызов строит очередь из одного элемента. Попытка добавить в эту очередь элемент b может удивить: непонятно, куда исчез элемент a. Но ничего удивительного в полученном результате нет - ведь функция TCONC не модифицирует второй аргумент. Поэтому новая очередь после возврата уничтожается. Чтобы очередь сохранялась, следует результат TCONC явно присвоить второму аргументу (как это и делается при последующих вызовах).
|
|
UNION |
Функция UNION является теоретико-множественной. Она строит список, содержащий объединение
элементов, входящих в значения двух ее списков-аргументов. Естественно, что каждый из элементов
входит в объединение в едиственном числе.
Вот примеры работы с функцией UNION :
(union '(1 1 1 2 2 2) '(1 2 3)) ==> (3 2 1) |
Видно, что функция UNION строит список, содержащий атомы, входящие в списки (1 1 1 2 2 2) и (1 2 3).
